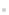【摘要】如何对海量的DPI数据进行实时的采集以及处理是运营商研究的热点,传统基于MapReduce的批处理模式难以满足流式计算实时性要求,因此首先介绍了流式处理相关概念,然后分析了目前流行的流式计算技术,提出一种基于流式计算的DPI数据处理方案,并应用在实际项目中,满足电信运营商对数据处理实时性的要求,最后通过实践总结了流式处理的应用场景。
【关键词】DPI;流式计算;数据处理
doi:10.3969/j.issn.1006-1010.2018.01.000 中图分类号:TN399 文献标志码:A 文章编号:1006-1010(2018)01-0000-00
引用格式:范家杰,田熙清. 基于流式计算的DPI数据处理方案及实践[J]. 移动通信, 2017,42(1): 00-00.
Scheme and Practice of DPI Data Processing Based on Stream Computing
FAN Jiajie, TIAN Xiqing
(Guangdong Research Institute of China Telecom Co., Ltd., Guangzhou 510630, China)
[Abstract] How to collect and process the massive DPI data in real time is the hotspot of telecom operators. The traditional batch mode MapReduce is difficult to meet the real-time requirements based on stream calculation, so this paper firstly introduces the related concepts of stream computing, and then analyzes the current popular streaming technology, presents a stream computing based on the DPI data processing program. This scheme is applied to practical projects to meet the requirements of telecom operators for real-time data processing. Finally, the application scenarios of streaming processing are summarized through practice.
[Key words] DPI; stream computing; data processing
1 引言
随着移动互联网的不断发展以及各类智能设备日益深入民众日常生活中,人类社会产生的数据量正在以指数级快速增长,人类已经正式迈入大数据时代[1]。如今,运营商能够获得的用户数据越来越丰富,通过DPI(Deep Packet Inspector,深度分组检测)分析技术,能够较好地识别网络上的流量类别、应用层上的应用种类等[2]。在这个“数据为王”的时代,如何充分利用这笔重要的战略资产已成为重中之重。
数据规模的快速增长给大数据分析处理带来了巨大的挑战,尤其是在通信行业,数据越发呈现出无限性、突发性和实时性等特征[3],传统的基于MapReduce的批处理模式难以满足数据实时性的要求,而能否在第一时间获得数据所蕴含的信息决定了数据的价值。因此,流式处理技术成为大数据技术研究的新热点[4]。流式处理能够针对数据的变化进行实时处理,能够在秒级获得处理结果,特别适合一些对时效性要求很高的场景。
本文结合电信运营商的需求,对DPI数据进行实时的采集及处理,提出一种基于流式计算的DPI数据处理方案,能够将获得DPI数据实时信息的时延降低到分钟级,甚至秒级,实现对电信用户上网信息的实时处理、监测及分类汇总,为之后进行的大数据应用提供了良好基础。
2 流式处理概述
传统基于MapReduce大数据处理技术实际上是一种批处理方式,如图1所示。批处理模式首先要完成数据的累积和存储,然后Hadoop客户端将数据上传到HDFS上,最后才启动Map/Reduce进行数据处理,处理后再写入到HDFS。这种方式必须要所有数据都要准备好,然后统一进行集中计算和价值发现,无法满足实时性的要求。

图1 基于MapReduce的大数据处理
2015年,Nathan Marz提出了实时大数据处理框架Lambda架构[5],整合了离线计算和实时计算,能够满足实时系统高容错、低时延和可扩展等要求,并且可集成Hadoop、Kafka、Storm、Spark及HBase等各类大数据组件。
一个典型的Lambda架构如图2所示,主要使用的场景是逻辑复杂且延迟低的程序。数据会分别灌入实时系统和批处理系统,然后各自输出自己的结果,结果会在查询端进行合并。
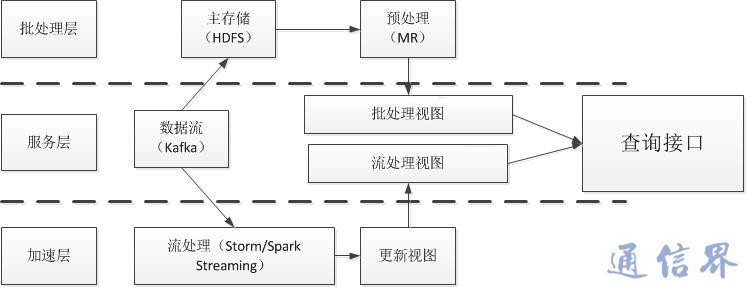
图2 Lambda架构图
3 流式计算架构对比
流式计算对系统的容错、时延、可扩展及可靠性能力提出了很高的要求,当前有许多流式计算框架(如Spark streaming[10]、Storm[11]、Kafka Stream[12]、Flink[13]和PipelineDB[14]等)已经广泛应用于各行各业,并且还在不断迭代发展,适用的场景也各不相同。
3.1 Spark streaming
Spark是由加州大学伯克利分校AMP实验室专门为大数据处理而设计的计算框架[6]。Spark Streaming是建立在Spark上的实时计算框架,是Spark的核心组件之一,通过它内置的API和基于内存的高效引擎,用户可以结合流处理、批处理和交互式查询开发应用。
Spark Streaming并不像其他流式处理框架每次只处理一条记录,而是将流数据离散化处理,每次处理一批数据(DStream),使之能够进行秒级以下的快速批处理,执行流程如图3所示。Spark Streaming的Receiver并行接收数据,将数据缓存至内存中,经过延迟优化后Spark引擎对短任务(几十毫秒)进行批处理。这样设计的好处让Spark Streaming能够同时处理离线处理和流处理问题。
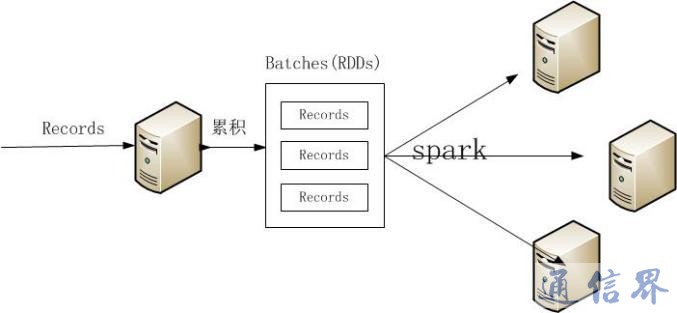
图3 Spark Streaming执行流程
Spark Streaming能在故障报错下迅速恢复状态,整合了批处理与流处理,内置丰富高级算法处理库,发展迅速,社区活跃。毫无疑问,Spark Streaming是流式处理框架的佼佼者。缺点是由于需要累积一批小文件才处理,因此时延会稍大,是准实时系统。
3.2 Storm
Storm通常被比作“实时的Hadoop”,是Twitter开发的实时、分布式以及具备高容错计算系统,可以简单、可靠地处理大量数据流,用户可以采用任意编程语言来开发应用。
在Storm中,一个用于实时计算的图状结构称之为拓扑(topology),拓扑提交到集群,由集群中的主控节点分发代码,分配任务到工作节点执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成映射map、过滤filter等操作,bolt自身也可以随机将数据发送给其他bolt。
图4 Storm数据流动
Storm能将数据在不同的bolt中流动、移动数据,真正实现流式处理,易于扩展,灵活性强,高度专注于流式处理。Storm在事件处理与增量计算方面表现突出,能够以实时方式根据不断变化的参数对数据流进行处理。
3.3 Kafka Stream
Kafka Stream是Apache Kafka开源项目的一个组成部分,是一个功能强大、易于使用的库,它使得Apache Kafka拥有流处理的能力。
Kafka Stream是轻量级的流计算类库,除了Apache Kafka之外没有任何外部依赖,可以在任何Java程序中使用,使用Kafka作为内部消息通讯存储介质,因此不需要为流处理需求额外部署一个集群。
Kafka Stream入门简单,并且不依赖其他组件,非常容易部署,支持容错的本地状态,延迟低,非常适合一些轻量级流处理的场景。
3.4 Flink
Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,同时支持批处理以及流处理,主要针对流数据,将批数据视为流数据的一个极限特例。
Flink核心是一个流式的数据流执行引擎,它提供了数据分布、数据通信以及容错机制等功能。流执行引擎之上,Flink提供了更高层次的API以便用户使用。Flink还针对某些领域提供了领域库,例如Flink ML、Flink的机器学习库等。
Flink适合有极高流处理需求,并有少量批处理任务的场景。该技术可兼容原生Storm和Hadoop程序,可在YARN管理的集群上运行。目前Flink最大的局限之一是在社区活跃度方面,该项目的大规模部署尚不如其他处理框架那么常见。
3.5 PipeLineDB
PipelineDB是基于PostgreSQL的一个流式计算数据库,效率非常高,通过SQL对数据流做操作,并把操作结果储存起来。其基本过程是:创建PipelineDB Stream、编写SQL、对Stream做操作、操作结果被保存到continuous view。
PipelineDB特点是可以只使用SQL进行流式处理,不需要代码,可以高效可持续自动处理流式数据,只存储处理后的数据,因此非常适合流式数据处理,例如网站流量统计、网页的浏览统计等。
3.6 架构对比
上文提到的5种流式处理框架对比如表1所示:
表1 流式框架对比
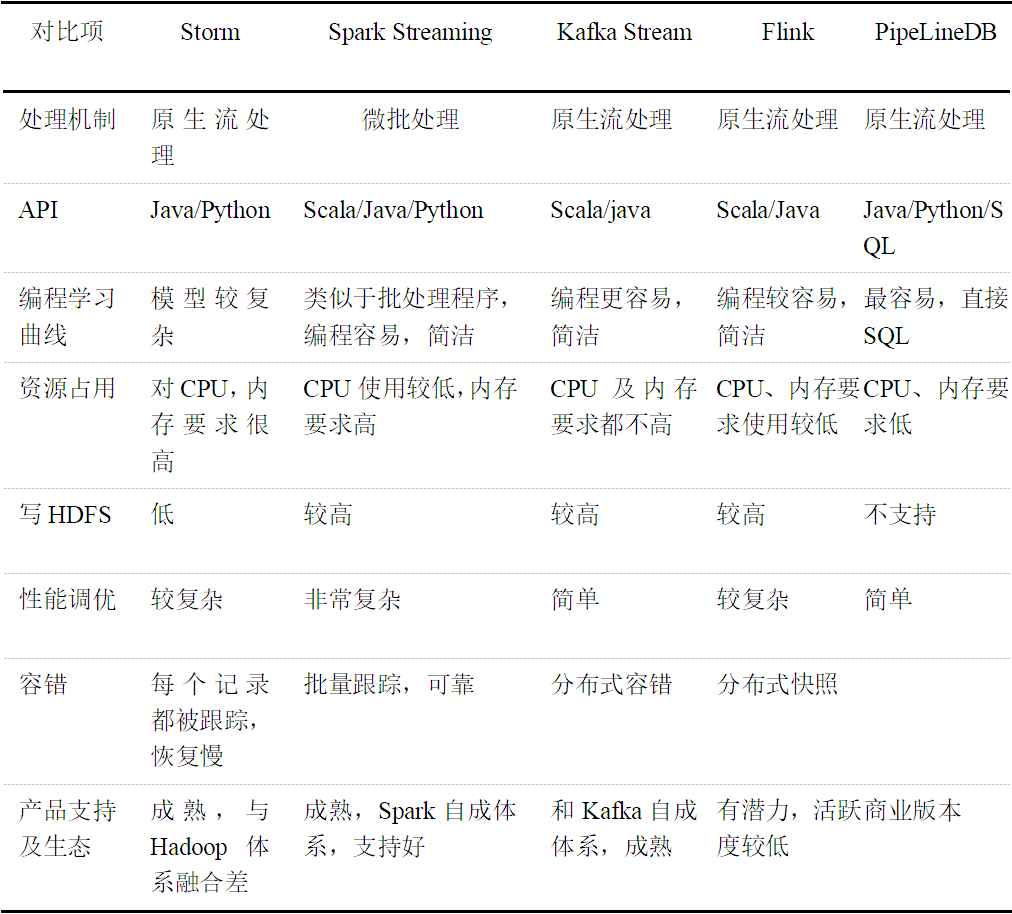
Storm的特点是成熟,是流式处理框架实际上的标准,模型、编程难度都比较复杂,框架采用循环处理数据,对系统资源,尤其是CPU资源消耗很大,当任务空闲时,需要sleep程序,减少对资源的消耗。Spark Streaming兼顾了批处理以及流式处理,并且有Spark的强大支持,发展潜力大,但与Kafka的接口平滑性不够。Kafka Stream是Kafka的一个开发库,具有入门、编程、部署运维简单的特点,并且不需要部署额外的组件,但对于多维度的统计来说,需要基于不同topic来做分区,编程模型复杂。Flink跟Spark Streaming很像,不同的是Flink把所有任务当成流来处理,在迭代计算、内存管理方面比Spark Streaming稍强,缺点是社区活跃度不高,还不够成熟;PipelineDB是一个流式计算数据库,能执行简单的流式计算任务,优势是基本不需要开发,只要熟悉SQL操作均可以轻松使用,但对于集群计算,需要商业上的支持。
4 DPI数据处理方案
基于实际任务需求以及上文流式框架的对比,由于Kafka Stream编程难度小,不需要另外安装软件,与Kafka等组件无缝连接,比较稳定,并且各种性能均比较优秀,因此本文选择了Kafka Stream作为流式处理的核心组件。
4.1 宽带DPI处理
为了完成宽带DPI数据的实时抓包、资料填补、清洗、转换及并入库等工作,应用了上述DPI数据处理方案。具体项目方案如图5所示:
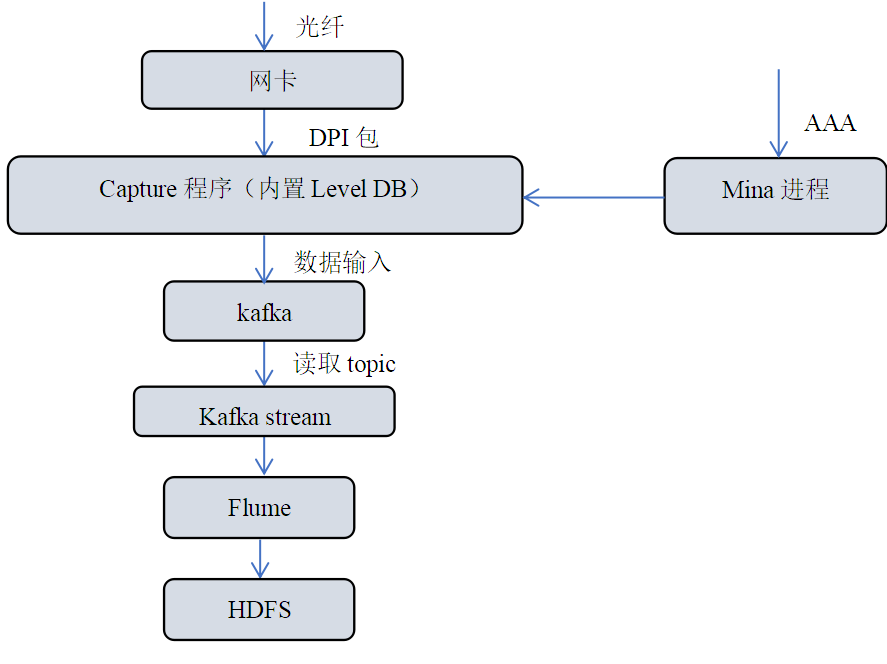
图5 广州宽带DPI处理方案
Mina进程是一个JAVA程序,基于mina框架开发,主要接收AAA数据包,获得用户账户信息,解析计算,并持久化到redis,最后发送给抓包(Capture)程序。Capture程序由C语言编写,使用开源pcap抓取网卡http包,解析,结合用户帐号资料,把DPI写入到Kafka中。Kafka stream完成DPI的实时清洗和转换工作。
Flume[15]是Cloudera开源的分布式可靠、可用、高效的收集,聚合和移动不同数据源的海量数据系统,配置简单,基本无需开发,资源消耗低,支持传输数据到HDFS,非常适合与大数据系统结合。本项目将流式处理完后的数据通过Flume从Kafka中写入到HDFS,建立hive表,为上层应用提供数据。
Kafka Stream采用自主研发的ETL框架[16],负责数据过滤(图片、视频等去掉),数据处理(获取网络ID、字段解析等)。ETL框架采用JAVA语言开发,支持多种数据源,包括普通文本、压缩格式及xml立体格式等。支持多种大数据计算框架,包括Map/Reduce、Spark streaming、Kafka Stream和Flume等;具有扩展方便、字段校验、支持字段的通配符及支持维表查询等功能。在运维方面,支持变量引用以及出错处理等功能。
4.2 4G DPI实时统计
以电信4G DPI信息作为数据源,通过流式处理,完成DPI的实时统计工作,包括多粒度(5分钟/1小时/1天)去重用户统计、多粒度去重不同号码头用户统计、多粒度流量统计及多粒度去重域名统计等。4G DPI实时统计具体项目方案如图6所示:
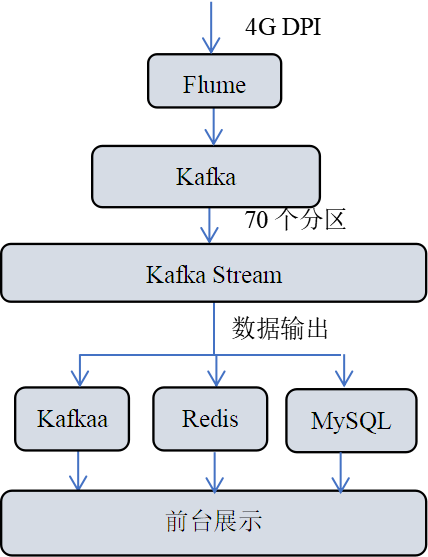
图6 4G DPI实时统计方案图
数据源是gzip压缩文件,因为flume原生不支持.gz或.tar.gz文件格式,所以修改了Flume底层代码,实现对压缩文件的处理,省去了解压时间。Flume采集文件时以用户手机号码作为分区的key,将同一号码的数据分到同一分区,便于去重。通过Kafka集群管理工具,Kafka Manager[17]可以很好地监测Kafka集群的状态。Kafka集群生产者如图7所示:
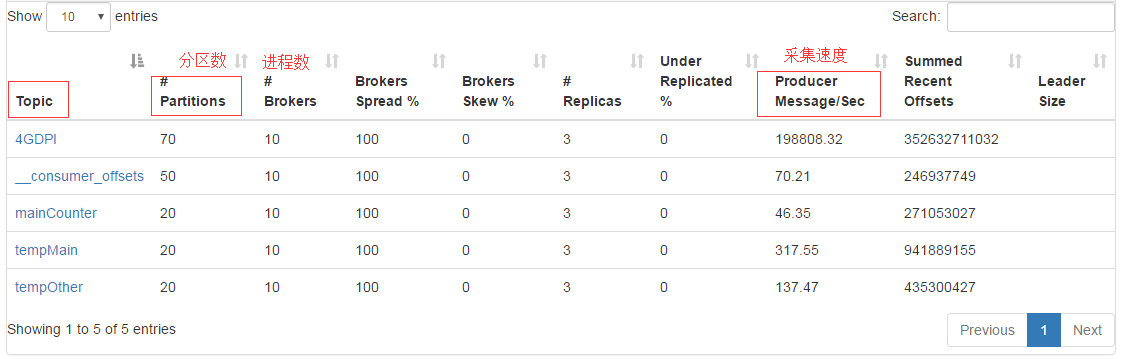
图7 Kafka集群生产者
Kafka Stream消费4GDPI的数据,并行处理。在程序里设置不同的计数器,所有数据都经过这些计数器处理,为了解决去重问题,引入了布隆过滤,虽然有一定的误判率,但是还是能比较好的完成去重,同时保证系统的性能。同样消费者也可以通过Kafka Manager进行管理,可以直观观察到消费者的落后程度。
为了满足不同的输出要求,程序设置了三种输出供选择。粒度为天的数据将会写到MySQL作为备份,针对热点区域的监控数据将会输出到Redis,同时,为了方便管理以及数据呈现,还采用了ELK框架(ElasticSearch+Logstash+Kibana),将所有数据传到Kibana做前端展示。Kibana界面如图8所示:
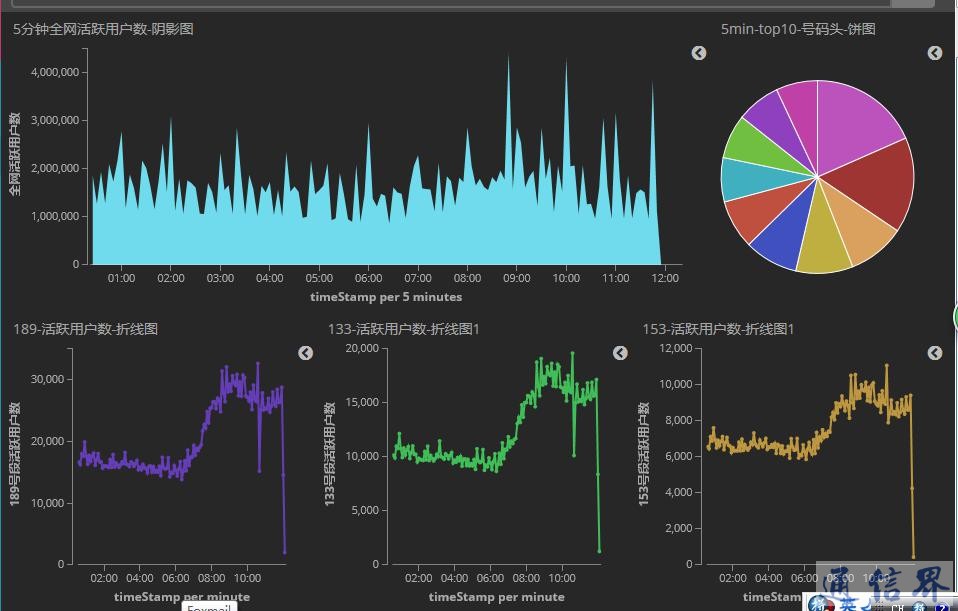
图8 Kibana界面
5 实践及分析
5.1 部署实践
上述两个系统均已应用在实际的生产中,均有不错的表现,能够满足任务需求,并且已经稳定运行。
宽带DPI处理项目有2台采集机、1台AAA服务器及5台Kafka机器。采集机每台每秒产生115 MB数据,两台1.8 G流量。采集机写Kafka 33万条/秒,Kafka Stream写Kafka 22万条/秒,清洗率(清洗工作把诸如图片、视频及js请求等与业务无关的DPI信息去掉)为33%。Kafka Stream落后处理稳定在500万数据,延迟处理在15 s之内,Flume写HDFS落后保持在100万左右,5 s内的延迟。宽带DPI处理项目性能如图9所示:
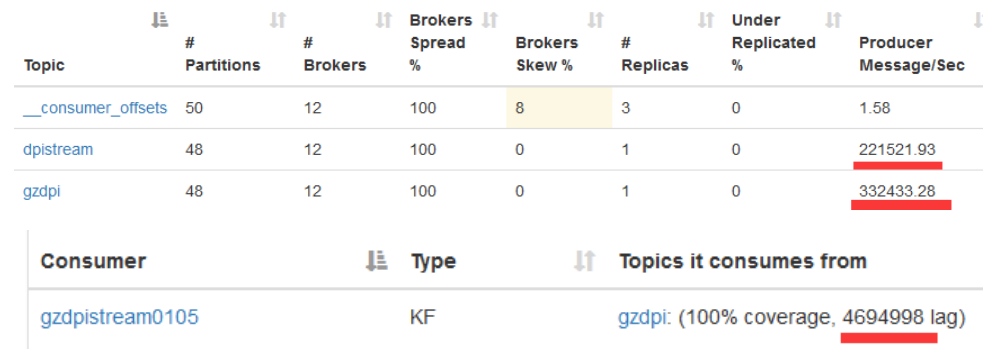
图9 宽带DPI处理项目性能
4G DPI实时统计项目共6台机器,1台为Flume采集机,其余5台部署Kafka、Kafka Stream及ELK。采集机写Kafka一般为10万条/秒,峰值可达到25万条/秒。ElasticSearch集群一共8个实例,每个实例配置2 G内存。目前集群有13亿条数据,占361 G空间。通过Logstash导入数据到ElasticSearch峰值可以达到8~9万条/秒。Kafka Stream处理数据落后在10 s内,Logstash写ElasticSearch落后在5 s内,如图10所示。目前4G DPI实时统计项目日均处理文件超过15 000个,大小达到1.6 T,日均处理记录数超过100亿。
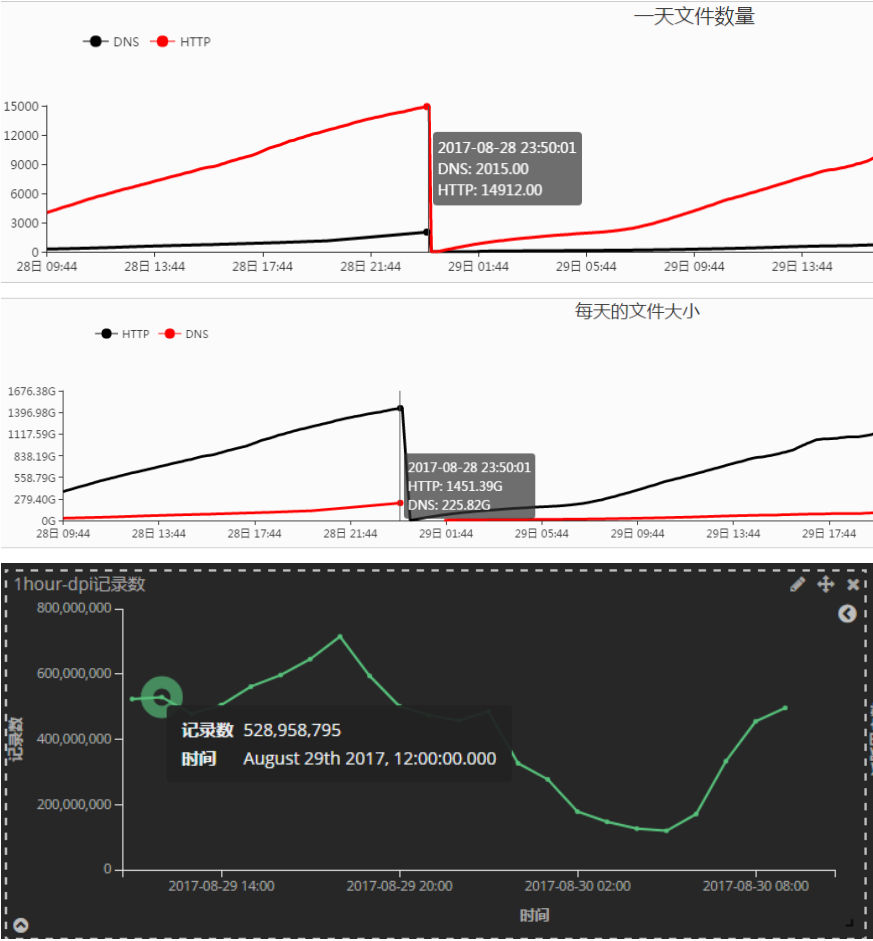
图10 4G DPI实时统计项目性能
5.2 存在的问题
在4G DPI实时统计项目开发过程中,随着项目的需求越来越多,后面增加了对域名和CGI的去重,而且同一域名或者CGI不在同一Kafka分区,导致结果有偏差。为了解决这一问题,程序设计了二次去重,第一次去重的结果把CGI或者域名作为key输出到Kafka集群,再做了一次去重工作,导致延迟时间变大和系统维护变复杂。
由于宽带DPI处理中不涉及去重,只是数据过滤和数据转换,因此Kafka Stream是非常适合的。但在涉及分区和去重的4G DPI实时统计项目中,应当采用Storm作为流式处理框架。在Storm中,数据从一个bolt流到另外一个bolt,这样数据可以在一个bolt中按手机号码分区,在另外一个bolt中又可以按CGI或者域名分区,可以避免二次去重问题,降低编程模型复杂度。
在程序设计之初,应根据应用场景需求选择合适的技术框架。如果项目基础结构中涉及Spark,那Spark Streaming是不错的选择;如果像4G DPI实时统计项目一样需要数据转移或者去重,那么Storm是首选;如果是简单的数据清洗和转换处理,那么Kafka Stream是不错的选择。对于简单小规模的实时统计,PipeLineDB足以胜任。
6 结束语
大数据流式计算和批处理适用于不同的业务场景,在对时效要求高的场景下,流式计算具有明显的优势。本文首先概述了流式处理以及其与批处理的区别,然后对业界流行的流式计算框架进行了对比,根据业务需求提出了以Kafka Stream为流式处理框架的DPI数据处理方案,搭配Kafka、Flume及ELK等组件,具有入门迅速、编程难度低和部署维护简单等特点。并且将方案应用到了宽带DPI处理项目以及4G DPI实时统计项目中,完成了任务需求,性能优异,运行稳定。
在对实际项目实践中,随着任务需求的增多,发现Kafka Stream在应对多维度数据去重问题时表现不力,需要引入二次过滤来解决问题。因此在项目需求阶段,便要在技术框架选型时充分考虑可能出现的问题,结合技术框架适用场景,综合考虑。
[1] Zikopoulos P, Eaton C. Understanding Big Data: Analytics for Enterprise Class Hadoop and Streaming Data[M]. McGraw-Hill Osborne Media, 1989.
[2] 陈康,付华峥,陈翀,等. 基于DPI的用户兴趣实时分类[J]. 电信科学, 2016,32(12): 109-115.
[3] 孙大为,张广艳,郑纬民. 大数据流式计算:关键技术及系统实例[J]. 软件学报, 2014,25(4): 839-862.
[4] 董斌,杨迪,王铮,等. 流计算大数据技术在运营商实时信令处理中的应用[J]. 电信科学, 2015,31(10): 165-171.
[5] Marz N,Warren J. Big Data: Principles and best practices of scalable realtime data systems[M]. Manning, 2015.
[6] 李祥池. 基于ELK和Spark Streaming的日志分析系统设计与实现[J]. 电子科学技术, 2015,2(6): 674-678.
[7] 李圣,黄永忠,陈海勇. 大数据流式计算系统研究综述[J]. 信息工程大学学报, 2016,17(1): 88-92.
[8] 姚仁捷. Kafka在唯品会的应用实践[J]. 程序员, 2014(1): 110-113.
[9] 郝璇. 基于Apache Flume的分布式日志收集系统设计与实现[J]. 软件导刊, 2014(7): 110-111.
[10] Spark. Spark Streaming Programming Guide[EB/OL]. [2017-09-14]. http://spark.apache.org/docs/latest/streaming-programming-guide.html.
[11] Storm. Apache Storm[EB/OL]. [2017-09-14]. http://storm.apache.org/index.html.
[12] Kafka Stream. Kafka Streams API[EB/OL]. [2017-09-14]. http://kafka.apache.org/documentation/streams/.
[13] Flink. Introduction to Apache Flink®[EB/OL]. [2017-09-14]. https://flink.apache.org/introduction.html.
[14] PipelineDB. The Streaming SQL Database[EB/OL]. [2017-09-14]. https://www.pipelinedb.com/.
[15] Apache Flume™. Apache Flume™[EB/OL]. [2017-09-14]. http://flume.apache.org/index.html.
[16] Kafka Stream. ETL[EB/OL]. [2017-09-14]. https://github.com/styg/bumblebee-ETL.
[17] Kafka Stream. Kafka Manager[EB/OL]. [2017-09-14]. https://github.com/yahoo/kafka-manager. ★
作者简介
田熙清:硕士毕业于大连理工大学系统工程专业,现任职于中国电信股份有限公司广州研究院,研究方向为大数据平台及处理。
范家杰:硕士毕业于中山大学,现任职于中国电信股份有限公司广州研究院,研究方向为大数据平台及处理。