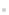ЈЁ1.№гЦЭҙуС§»ъРөУлөзЖш№ӨіМС§ФәЈ¬№г¶« №гЦЭ 510006Ј»2.№г¶«№ӨТөҙуС§ЦЗДЬјмІвУлЦЖФмОпБӘҪМУэІҝЦШөгКөСйКТЈ¬№г¶« №гЦЭ 510006Ј»3.№г¶«№ӨТөҙуС§ОпБӘНшЦЗДЬРЕПўҙҰАнУлПөНіјҜіЙҪМУэІҝЦШөгКөСйКТЈ¬№г¶« №гЦЭ 510006Ј©
0 ТэСФ
ГӨФҙ·ЦАлЈ¬УЦіЖГӨРЕәЕ·ЦАлЈ¬КЗЦёҪцёщҫЭҪУКХөД»мөюРЕәЕЈЁ№ЫІвРЕәЕЈ©·ЦАл»т»ЦёҙОҙЦӘФҙРЕәЕЈ¬ДҝөДКЗЗуөГФҙРЕәЕөДЧојС№АјЖ[1-2]ЎЈЖдТтЗҝҙуөД·ЦАл№ҰДЬТСФЪНЁРЕРЕәЕҙҰАн[3]ЎўЙъОпТҪС§РЕәЕҙҰАнЈЁРД·ОТфРЕәЕ·ЦАлөИЈ©[4]ЎўНјПсҙҰАн[5]ТФј°УпТфРЕәЕҙҰАн[6-7]өИ¶аБмУтөГөҪБЛ№г·әөДУҰУГЎЈФЪКөјКөДРЕәЕҪУКХ№эіМЦРЈ¬ҙ«ёРЖчөДКэДҝНщНщРЎУЪФҙРЕәЕөДКэДҝЈЁјҙЗ·¶Ё»мөюЈ©Ј¬өјЦВНЁөАөДГӨұжК¶ј«ҫЯМфХҪРФЈ¬МШұрКЗФЪёЯ»мПмёҙФУ»·ҫіПВЈ¬ҝЙМэ»ШЙщ¶ФТфЦКУРЧЕЦШТӘөДУ°ПмЈ¬өјЦВҪУКХРЕәЕҫЯУРёҙФУРФЈ¬ёшФҙРЕәЕөД·ЦАлҙшАҙБЛҫЮҙуөДМфХҪЈ¬ҙ«НіөДГӨФҙ·ЦАлЛг·ЁОЮ·Ёі№өЧҪвҫцёГАаОКМвЎЈ
¶ФИЛАаМэҫхПөНіМШРФөДСРҫҝұнГчЈ¬өұ»ШЙщөНУЪУЙЦұҪУЙщТфТэЖрөДСЪұОј«ПЮКұЈ¬Ҫ«МэІ»өҪ»ШЙщЈ¬ХвҫНКЗИЛАаМэҫхПөНіөДКұјдСЪұОР§УҰ[8-9]ЎЈөұ»ШЙщёХәГөНУЪСЪұОј«ПЮКұИЛАаМэҫхПөНіКЗМэІ»јыөДЈ¬ИЛАаМэҫхПөНі¶ФДЗР©і¬№эСЪұОј«ПЮөД»ШЙщ·ЗіЈГфёРЎЈФЪөН»мПм»·ҫіПВЈ¬ҝЙАыУГҝХјдВціеПмУҰЦШЛЬјјКхНкИ«ПыіэҝЙМэ»ШЙщЈ¬¶шІ»У°ПмЙщТфөДЦКБҝЎЈИ»¶шЈ¬ФЪёЯ»мПм»·ҫіПВЈ¬ҝЙМэ»ШЙщөДҙжФЪКЗІ»ҝЙұЬГвөДЈ¬¶ФҙЛЈ¬Т»Р©ёДҪшөДҝХјдВціеПмУҰЦШЛЬјјКхұ»Мбіц[10-11]ЎЈЖдЦРЈ¬Jungmann өИ[10]ҪбәПЙщС§¶аКдИл¶аКдіцРЕөАҙ®ИЕПыіэәНҝХјдВціеПмУҰЦШЛЬјјКхҪөөНБЛ»мПмөДУ°ПмЎЈMertins өИ[11]МбіцөД»щУЪН№ХэФт»ҜјјКхКөПЦБЛҝХјдВціеПмУҰЦШЛЬәНҙ®ИЕПыіэЎЈИ»¶шЈ¬ТФЙПСРҫҝЦчТӘјҜЦРУЪҝХјдВціеПмУҰЦШЛЬјјКхұҫЙнЈ¬¶ш»щУЪёГјјКхөДГӨФҙ·ЦАлСРҫҝЙРІ»¶ајыЎЈјшУЪҙЛЈ¬ұҫОДФЪГӨФҙ·ЦАлЛг·ЁЦРТэИлҝХјдВціеПмУҰЦШЛЬјјКхЈ¬НЁ№эёДҪшёГјјКхТФј°ЙијЖРВөДГӨФҙ·ЦАлЛг·ЁЈ¬МбіцГжПтёЯ»мПмёҙФУ»·ҫіөДЗ·¶Ёҫн»эГӨФҙ·ЦАлЛг·ЁЎЈ
ДҝЗ°Ј¬ұИҪПБчРРөДГӨФҙ·ЦАлЛг·ЁЦчТӘАыУГ¶МКұёөАпТ¶ұд»Ҝ°СКұУт»мөюРЕәЕЧӘ»»өҪЖөУтЦРЈ¬ёщҫЭРЕәЕФЪЖөУтЙПөДНіјЖМШРФ[12]Ўў¶АБўРФ[13]Ўў·ЗёәРФ[14]ЎўПЎКиРФ[15]өИРФЦКЈ¬ЙијЖПаУҰөДКұЖөУтГӨФҙ·ЦАлЛг·ЁЎЈФЪДЈРНұд»»№эіМЦРЈ¬°СКұУтЙПөДҫн»э»мөюұд»»іЙЖөУтЙПөДЛІКұПЯРФ»мөюЈ¬јхЙЩБЛКұУтҫн»эјЖЛгҙшАҙөДёҙФУРФЎЈФЪөН»мПм»мөю»·ҫіПВЈ¬ёГДЈРНұд»»ҫЯУРҪПөНөДҪьЛЖОуІоЈ¬УЙҙЛСЬЙъіцТ»ПөБРЗ·¶Ёҫн»эГӨФҙ·ЦАлЛг·Ё[16-19]ЎЈЖдЦРЈ¬ОДПЧ[16-17]»щУЪБӘәПҫШХуҝй¶ФҪЗ»Ҝ·Ҫ·ЁЈ¬КөПЦБЛҫн»э»мөюРЕәЕөДГӨФҙ·ЦАлЈ»ОДПЧ[18-19]»щУЪҫШХуЧҙМ¬Рӯ·ҪІоДЈРНЈ¬МбіцБЛөьҙъЖЪНыЧоҙу»ҜЛг·Ё№АјЖДЈРНІОКэЈ¬НЁ№эКөКұёьРВУЕ»ҜДЈРНІОКэЈ¬ФЩУГО¬ДЙВЛІЁ·Ё·ЦАлФҙРЕәЕЎЈИ»¶шЈ¬ХвАаЛг·ЁКХБІЛЩ¶ИКЬПЮЈ¬¶шЗТ¶ФНЁөАҪЧКэУлЛг·ЁіхКј»ҜҪПГфёРЎЈ
·ЗёәҫШХу·ЦҪвКЗТ»ЦЦ»ъЖчС§П°Лг·ЁҝтјЬЈ¬Ҫ«·ЗёәҫШХу·ЦҪвОӘ2 ёцөНЦИ·ЗёәТтЧУҫШХуөДіЛ»э[20]Ј¬ФЪҙҰАнҫн»э»мөюГӨФҙ·ЦАлОКМвЦРЈ¬НЁ№эҪ«ФҙРЕәЕөД№ҰВКЖЧГЬ¶ИҫШХу·ЦҪвОӘ2 ёц·ЗёәҫШХуөДіЛ»эЈ¬Т»ПөБР»щУЪ·ЗёәҫШХу·ЦҪвФҙДЈРНөДГӨФҙ·ЦАлЛг·Ёұ»Мбіц[21-23]ЎЈЖдЦРЈ¬Sawada өИ[21]»щУЪ·ЗёәҫШХу·ЦҪвөДөНЦИФҙДЈРНЈ¬АыУГ¶аФӘёҙёЯЛ№·ЦІјөДНіјЖДЈРН¶ЁТе¶аНЁөАЕ·јёАпөГҫаАләН¶аНЁөАISЈЁItakura-SaitoЈ©Йў¶ИЈ¬ОӘБЛЧоРЎ»ҜХвЦЦЙў¶ИЈ¬НЁ№эЙијЖККөұөДёЁЦъәҜКэЈ¬НЖөјіціЛ·ЁёьРВРОКҪөДУЕ»ҜЛг·ЁЈ»Sekiguchi өИ[22]јЩЙиФҙНјПсЧсСӯОЮФјКшИ«ЦИҝХјдРӯ·ҪІоҫШХуөД¶аФӘёҙёЯЛ№·ЦІјЈ¬Ҫ«ҝХјдРӯ·ҪІоҫШХуПЮЦЖОӘТФЖөВК·ҪКҪБӘәП¶ФҪЗ»ҜВъЦИҫШХуЈ¬ҙУ¶шКөПЦБЛҝмЛЩ¶аНЁөА·ЗёәҫШХу·ЦҪвЈ»Wang өИ[23]НЁ№эЧоРЎМе»эПИСй·ЦІјАҙФцЗҝФҙДЈРНөДҝЙК¶ұрРФЈ¬АыУГЧоРЎМе»эХэФт»Ҝ¶аНЁөА·ЗёәҫШХу·ЦҪвЈ¬Чоҙу»Ҝ·ЦАлФҙөДәуСй·ЦІјЈ¬ұЈЦӨБЛКХБІөДОИ¶ЁРФЎЈ
И»¶шЈ¬»щУЪ·ЗёәҫШХу·ЦҪвЙијЖөДУЕ»ҜЛг·Ё¶ФДЈРНІОКэөДіхКј»ҜұИҪПГфёРЈ¬ПЮЦЖБЛЛг·ЁөДЧФККУҰРФЎЈБнНвЈ¬КұУтЙПөДҫн»э»мөюДЈРННЁ№э¶МКұёөАпТ¶ұд»»ұд»»өҪЖөУтЙПөДЛІКұПЯРФ»мөюДЈРНКЗТ»ЦЦҪьЛЖұд»»ДЈРНЈ¬ЖдіЙБўөДЗ°МбМхјюКЗ¶МКұёөАпТ¶ұд»»өДҙ°іӨ¶ИФ¶ҙуУЪВціеПмУҰөДіӨ¶ИЈ¬¶шФЪёЯ»мПм»·ҫіПВёГМхјюКЗәЬДСөГөҪВъЧгөДЈ¬ј«ТЧөјЦВҪПҙуөДДЈРНҪьЛЖОуІоЈ¬ЛщТФФЪҙЛұд»»ДЈРНПВЙијЖөДЛг·ЁНщНщІ»ККУГУЪёЯ»мПм»·ҫіЎЈ¶ФҙЛЈ¬ОДПЧ[24-25]Мбіц»щУЪҫн»эҙ«өЭәҜКэөДҫн»эХӯҙшҪьЛЖЈ¬ёГҫн»эҝнҙшҪьЛЖДЈРНДЬұЬГвТФЙПМхјюөДПЮЦЖЈ¬ёьҫ«ЧјөШҪьЛЖКұУтЙПөДҫн»эДЈРНЈ¬ККУГУЪёЯ»мПм»мөюЗйРОЈ¬ө«ЖдКЗҫн»эјЖЛгЈ¬ИЭТЧҙшАҙёьёЯөДјЖЛгБҝЎЈ
јшУЪДҝЗ°СРҫҝПЦЧҙЈ¬ГжПтёЯ»мПм»·ҫіөДЗ·¶Ёҫн»эГӨФҙ·ЦАлОКМвИФИ»ҙжФЪТФПВДСөгЎЈ
1) ФЪёЯ»мПмёҙФУ»·ҫіПВЈ¬ҝЙМэ»ШЙщәН»мПм¶ФТфЦКУРЧЕЦШТӘөДУ°ПмЈ¬өјЦВҪУКХРЕәЕҫЯУРёҙФУРФЎЈ
2) Иұ·Ұ¶ФёЯ»мПм»·ҫіПВЗ·¶Ёҫн»э»мөюРЕәЕҫ«И·өДКэС§ҪЁДЈЈ¬өјЦВДЈРНҪьЛЖОуІоФцҙуЎЈ
3) З·¶Ёҫн»э»мөюГӨФҙ·ЦАлКөЦКЙПКЗТ»ёц·ЗПЯРФОКМвЈ¬ЖдЗуҪвА§ДСЈ¬УЙУЪНвҪз»·ҫіөДёҙФУРФЈ¬өјЦВҙ«НіГӨФҙ·ЦАлЛг·ЁөДРФДЬКЬПЮЎЈ
Хл¶ФТФЙПОКМвЈ¬ұҫОДҙУҝХјдВціеПмУҰЦШЛЬөДҪЗ¶Иіц·ўЈ¬ҪбәПЗ·¶Ёҫн»эГӨФҙ·ЦАлСРҫҝЛјВ·Ј¬МбіцТ»ЦЦГжПтёЯ»мПм»·ҫіөДЗ·¶Ёҫн»эГӨФҙ·ЦАлЛг·ЁЎӘЎӘИ«ҫЦВціеПмУҰЗ·¶ЁГӨФҙ·ЦАлЈЁGIR-UBSS,global impulse response underdetermined blind source separationЈ©ЎЈұҫОДҙҙРВөгёЕАЁИзПВЎЈ
1) ЙијЖБЛИ«ҫЦВціеПмУҰНшВзЈ¬НЁ№эУЕ»ҜҝЙөчВЛІЁЖчПчИхҝЙМэ»ШЙщөДУ°ПмЈ¬МбёЯБЛРЕәЕөДЦКБҝЎЈ
2) №№ҪЁБЛГжПтёЯ»мПмёҙФУ»·ҫіөДКұЖөУт»мөюРЕәЕКэС§ДЈРНЈ¬ҪөөНБЛДЈРНҪьЛЖОуІоЈ¬¶ФёЯ»мПм»·ҫіҫЯУРҪПәГөДЧФККУҰРФЎЈ
3) МбіцБЛТ»ЦЦGIR-UBSS Лг·ЁЈ¬ЙијЖБЛРВДЈРНПВІОКэөДКөКұёьРВ№жФтЈ¬КөПЦБЛФҙРЕәЕөДГӨ·ЦАлЎЈАнВЫ·ЦОцУлТ»ПөБР·ВХжКөСйСйЦӨБЛGIR-UBSS Лг·ЁөДУРР§РФУлУЕФҪРФЎЈ
1 ОКМвГиКц
¶ФёЯ»мПм»·ҫіПВјЗВјөД»мөюРЕәЕҪшРРИзПВКэС§ҪЁДЈЎЈ
ЖдЦРЈ¬xj(t)КЗөЪjёцНЁөАјЗВјөД»мөюРЕәЕЈ¬КұјдtКЗБ¬РшөДЈ¬i= 1,2,Ўӯ,IКЗФҙРЕәЕКэДҝЈ¬j= 1,2,Ўӯ,JКЗҙ«ёРЖчКэДҝЈ¬a ji(t)КЗөЪiёцФҙРЕәЕөҪөЪjёцНЁөА№эіМЦРІъЙъөДҝХјдВціеПмУҰЈ¬si(t)КЗөЪiёцФҙРЕәЕ,ҰУКЗКұСУЈ¬LКЗВціеПмУҰөДіӨ¶ИЈ¬b(t)КЗФлЙщЎЈАыУГҫШХуПтБҝөДРОКҪЈ¬КҪ(1)ҝЙұнКҫОӘ
ЖдЦРЈ¬*КЗҫн»э·ыәЕЈ¬x(t) =[x1(t),Ўӯ,x J(t)]TЈ¬КЗ»мөюПөНіЎЈұҫОДҝјВЗёЯ»мПм»·ҫіПВөДЗ·¶Ёҫн»э»мөюГӨФҙ·ЦАлОКМвЈ¬јҙIЈҫJОӘЗ·¶Ё»мөюЈ¬ЗТҝХјд»мПмКұјдЦрҪҘФцҙуөјЦВёЯ»мПмЎЈГӨФҙ·ЦАлөДДҝөДКЗҪцёщҫЭҪУКХөД»мөюРЕәЕx(t)·ЦАлФҙРЕәЕs(t)ЎЈ
2 ұҫОДЛг·Ё
2.1 И«ҫЦВціеПмУҰНшВзөДЙијЖ
ФЪёЯ»мПм»·ҫіПВЈ¬ҪУКХөҪөД»мөюРЕәЕіЈіЈ°йЛж»мПм»ШЙщЈ¬ОӘБЛПыіэ»тПчИхҝЙМэ»ШЙщөДУ°ПмЈ¬ұҫОДЙијЖТ»ЦЦИ«ҫЦВціеПмУҰНшВзЈ¬ИзНј1 ЛщКҫЈ¬ёГНшВзЙијЖЛјВ·АҙФҙУЪРЕөАҙ®ИЕПыіэәНҝХјдВціеПмУҰЦШЛЬјјКх[10]ЎЈ
Нј1 И«ҫЦВціеПмУҰНшВзөДЙијЖБчіМ
ҝјВЗФЪҪУКХЖчЗ°°ІЧ°LёцА©ТфЖчЈ¬ЖдЦРЈ¬IёцФҙРЕәЕҫӯ№эLёцА©ТфЖчҙ«өЭөҪJёцҪУКХЖчЈ¬hliКЗөЪiёцФҙРЕәЕНЁ№эөЪlёцА©ТфЖчІъЙъөДВціеПмУҰЈ¬ЖдіӨ¶ИОӘLhЈ¬AjlКЗөЪlёцА©ТфЖчөҪҙпөЪjёцҪУКХЖчІъЙъөДҝХјдВціеПмУҰЈ¬іӨ¶ИОӘLaЈ¬ФтҙУөЪiёцФҙРЕәЕөҪҙпөЪjёцҪУКХЖчІъЙъөДИ«ҫЦВціеПмУҰҝЙТФұнКҫОӘ
Жд ЦРЈ¬N1=t0fsЈ¬N2=ҰБfsЈ¬N3=Lg-N1-N2Ј¬n=0,Ўӯ,N3-1Ј»ҰБәНҰВКЗҝЙөчІОКэЈ¬ФЪЙијЖВЛІЁЖч№эіМЦРЈ¬НЁ№эөчҪЪЖдЦөөГөҪІ»Н¬өДҙ°әҜКэЈ¬КөПЦІ»Н¬өДВЛІЁДҝөДЎЈ
ЧоРЎ»ҜІ»ЖЪНыІҝ·ЦН¬КұЧоҙу»ҜЖЪНыІҝ·ЦЈ¬ҝјВЗУЕ»ҜОКМв
ЖдЦРЈ¬puәНpdКЗҝЙөчөДХэХыКэЈ¬НЁ№эөчҪЪЖдЦөЙијЖІ»Н¬·¶КэөДЛг·ЁЈ¬КөПЦІ»Н¬өДВціеПмУҰЦШЛЬР§№ыЎЈ
АыУГМЭ¶ИПВҪө·Ё¶ФКҪ(11)ЗуЖ«өјЈ¬өГөҪ
2.2 З·¶Ёҫн»эГӨФҙ·ЦАлЛг·ЁөДЙијЖ
2.2.1 ДЈРНұд»»
ОӘҪвҫцДЈРНКҪ(2)ПВөДГӨФҙ·ЦАлОКМвЈ¬ҙ«НіөД·Ҫ·ЁАыУГ¶МКұёөАпТ¶ұд»»өГөҪЖөУтЙПҪьЛЖөДПЯРФ»мөюДЈРНЈ¬ұнКҫОӘ
ЖдЦРЈ¬f=1,Ўӯ,FКЗЖөөгЦёКэЈ¬FКЗ¶МКұёөАпТ¶ұд»»өДҙ°іӨ¶ИЈ¬n=1,Ўӯ,NКЗКұјдҙ°ЦёКэЈ¬әН·ЦұрКЗx(t)Ўўs(t)әНb(t)НЁ№э¶МКұёөАпТ¶ұд»»өГөҪөДЈ¬ФлЙщb(t)КЗДЈДвПЦКөЙъ»оЦРөДХжКөФлЙщЈ¬КЗЖөУтЙПөДВціеПмУҰ»мөюҫШХуЎЈИ»¶шЈ¬ХвЦЦұд»»іЙБўөДЗ°МбМхјюКЗ¶МКұёөАпТ¶ұд»»өДҙ°іӨ¶ИFФ¶ҙуУЪВціеПмУҰөДіӨ¶ИLЈ¬јҙF≫LЎЈФЪёЯ»мПм»·ҫіПВЈ¬ЛжЧЕ»мПмКұјдЈЁRT,reverberation timeЈ©өДФцјУЈ¬ВціеПмУҰөДіӨ¶ИLЦрҪҘұдҙуЈ¬ЙхЦБі¬№эҙ°іӨ¶ИFЈ¬өјЦВПЯРФ»мөюДЈРНКҪ(16)ҪьЛЖОуІоФцҙуЈ¬ЙхЦБОЮР§ЎЈОӘБЛұЬГвХвЦЦПЮЦЖЈ¬ұҫОДЙијЖИ«ҫЦВціеПмУҰНшВзЈ¬Пыіэ»тПчИхҝЙМэ»ШЙщөДУ°ПмЈ¬Лх¶МВціеПмУҰөДіӨ¶ИЈ¬ҪөөНёЯ»мПм»·ҫіөДУ°ПмЈ¬ҪЁБўИзПВҪьЛЖДЈРНЎЈ
2.2.2 ·ЗёәҫШХу·ЦҪвДЈРН
јЩЙи[18]
2.2.3 ДЈРНІОКэөДёьРВ№жФт
ОӘБЛёьәГөШ·ЦОцЈ¬НЁ№эКҪ(34)әНКҪ(35)ұнКҫұЯјК·ЦІјәНіЙ¶ФБӘәПәуСй·ЦІјЈ¬јҙ
ТтҙЛЈ¬НЁ№эЙПКцјЖЛгgәНcөДәуСйНіјЖБҝЈ¬ҝЙЧоҙу»Ҝ¶ФКэЛЖИ»Ј¬ұнКҫОӘ
2.2.4 ЖөУтФҙРЕәЕөД№АјЖ
НЁ№эКөКұёьРВДЈРНІОКэЈ¬өГөҪЖөУтЙПөДФҙРЕәЕұнҙпКҪОӘ
ЧЫЙПЈ¬НЁ№эКҪ(46)»сөГЖөУтЙПөДФҙРЕәЕЈ¬ФЩАыУГ¶МКұёөАпТ¶Джұд»»өГөҪКұУтЙПөДФҙРЕәЕЈ¬КөПЦГӨФҙ·ЦАлЎЈ
3 КөСй
3.1 КөСйІОКэЙиЦГУлЖАјЫЧјФт
ОӘБЛДЈДвХжКө»·ҫіЈ¬АыУГ№ъјКЙП№«УГөДДЈДв»·ҫі·Ҫ·Ё[26]Ј¬ҙҙҪЁТ»ёцУРПЮВціеПмУҰ·ҝјдЈ¬ёГ·ҝјдөДО¬КэКЗ5mЎБ3mЎБ2.5mЈ¬№М¶Ё2 ёцҙ«ёРЖчЈ¬ЖдЧшұк·ЦұрОӘ[3 1 1.6]әН[3 1.05 1.6]Ј¬°СФҙРЕәЕ·ЕЦГФЪ3 ёцО»ЦГ[2 0.5 1.6]Ўў[2 1 1.6]әН[2 1.5 1.6]Ј¬јҙ3 ёцФҙРЕәЕБҪНЁөАөДЗ·¶Ё»мөюЈЁI= 2,J=3Ј©ЎЈRT ЙиЦГОӘ100Ў«900 msЈ¬ЦөФҪҙуЛөГч»мПміМ¶ИФҪЗҝЈ¬НЁ№эҙЛДЈДв»·ҫіІъЙъУР»мПмөДЗ·¶Ё»мөюРЕәЕЎЈФЪІОКэЙиЦГ·ҪГжЈ¬И«ҫЦВціеПмУҰНшВзЦРLa=Lh=fsRTЈЁfsОӘРЕәЕөДІЙСщЖөВКЈ©Ј¬ҰБ= 0.05Ј¬ҰВ=2.0Ј¬pu=10,pd=20Ј¬iter=1000Ј¬ҰМ= 10-6ЎЈФЪ·ЗёәҫШХу·ЦҪвФҙДЈРНЦРЈ¬ЙиЦГҰКi= 20Ј»ФЪІОКэіхКј»Ҝ·ҪГжЈ¬=IЈ¬ufkәНvknАыУГKLЈЁKullback-LeiblerЈ©Йў¶ИөД·ЗёәҫШХу·ЦҪв»сөГЈ¬ЗТЎЈ
ОӘБЛЖАјЫGIR-UBSS Лг·ЁөДУРР§РФЈ¬АыУГ№ъјК№«ИПөДЖАјЫЧјФтЈәРЕәЕК§ХжұИЈЁSDR,source-todistortion ratioЈ©ЎўРЕәЕёЙИЕұИЈЁSIR,source-tointerference ratio Ј©ЎўРЕәЕОұПсұИЈЁSAR,source-to-artifacts ratioЈ©[27]Ј¬ЖдЦөФҪҙуЈ¬ГӨФҙ·ЦАлРФДЬҫНФҪәГЎЈТтҙЛЈ¬АыУГЖАјЫЧјФтSDRЎўSIRЎўSARЦөөДҙуРЎәвБҝГӨФҙ·ЦАлөДәГ»өЎЈ
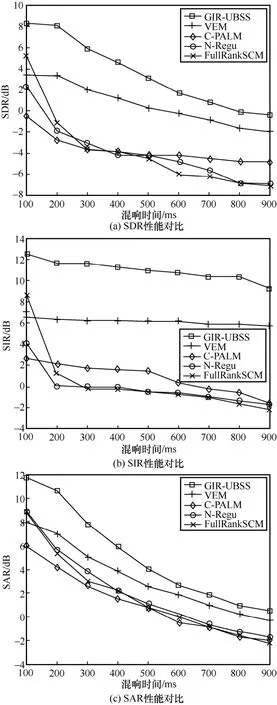
ОӘБЛЖАјЫGIR-UBSS Лг·ЁөДУЕФҪРФЈ¬¶ФұИДҝЗ°№ъјКЙПұИҪПБчРРөДјёЦЦГӨФҙ·ЦАлЛг·ЁЈәұд·ЦЖЪНыЧоҙу»ҜЈЁVEM,variational expectation-maximizationЈ©Лг·Ё[19]Ўўҫн»эҪь¶ЛҪ»МжПЯРФ»ҜЧоРЎ»ҜЈЁC-PALM,convolutive proximal alternating linearized minimizationЈ©Лг·Ё[24]ЎўҙшХэФт»ҜөДХӯҙшУЕ»ҜЈЁN-Regu,narrowband optimization with regularizatioЈ©Лг·Ё[24]ЎўИ«ЦИҝХјдРӯ·ҪІоДЈРНЈЁFullRankSCM,full-rank spatial covariance modelЈ©Лг·Ё[18]ЎЈЖдЦРЈ¬VEM Лг·ЁПИАыУГҝЁ¶ыВьЖҪ»¬Жч№АјЖ»мөюҫШХуәНФҙРЕәЕІОКэЈ¬ФЩУГО¬ДЙВЛІЁ·Ё·ЦАлФҙРЕәЕЎЈC-PALM Лг·ЁКЗТ»ЦЦҫн»эҪьЛЖҪ»МжПЯРФ»Ҝј«РЎ»Ҝ·Ҫ·ЁЈ¬НЁ№эАыУГҫн»эХӯҙшҪьЛЖ»сөГёьәГөДДЈРНҪьЛЖЈ¬јхЙЩБЛҫн»эәЛөДіӨ¶ИЈ¬ұЬГвБЛ¶МКұёөАпТ¶ұд»»ҙ°әҜКэіӨ¶ИөДПЮЦЖЎЈN-Regu Лг·ЁКЗТ»ЦЦҫӯөдөДҙшХэФт»ҜөДХӯҙшУЕ»Ҝ·Ҫ·ЁЈ¬АыУГБЛҙ«НіөДПЯРФХӯҙшҪьЛЖј°1-·¶КэХэФт»ҜЎЈFullRankSCM Лг·ЁАыУГВъЦИҝХјдРӯ·ҪІоДЈРНЈ¬КЗEM Лг·ЁЦРұИҪПіЙКмөД·Ҫ·ЁЦ®Т»ЎЈТФЙП¶ФұИЛг·ЁКЗҪвҫцЗ·¶Ёҫн»э»мөюГӨ·ЦАлОКМвЦРұИҪПБчРРөДЛг·ЁЈ¬НЁ№эУлХвР©БчРРөДГӨФҙ·ЦАлЛг·ЁҪшРР¶ФұИЈ¬ҝЙТФәЬәГөШЛөГчGIR-UBSS Лг·ЁөДУЕФҪРФЎЈН¬КұЈ¬ЛщУР¶ФұИЛг·ЁЦРөДІОКэј°ДЈРНІЙУГөДКЗУлұҫОДКөСйПаН¬өДЙиЦГЈ¬ХвСщ¶ФұИёьУРЛө·юБҰЎЈ
3.2 И«ҫЦВціеНшВзИҘ»мПмР§№ы·ЦОц
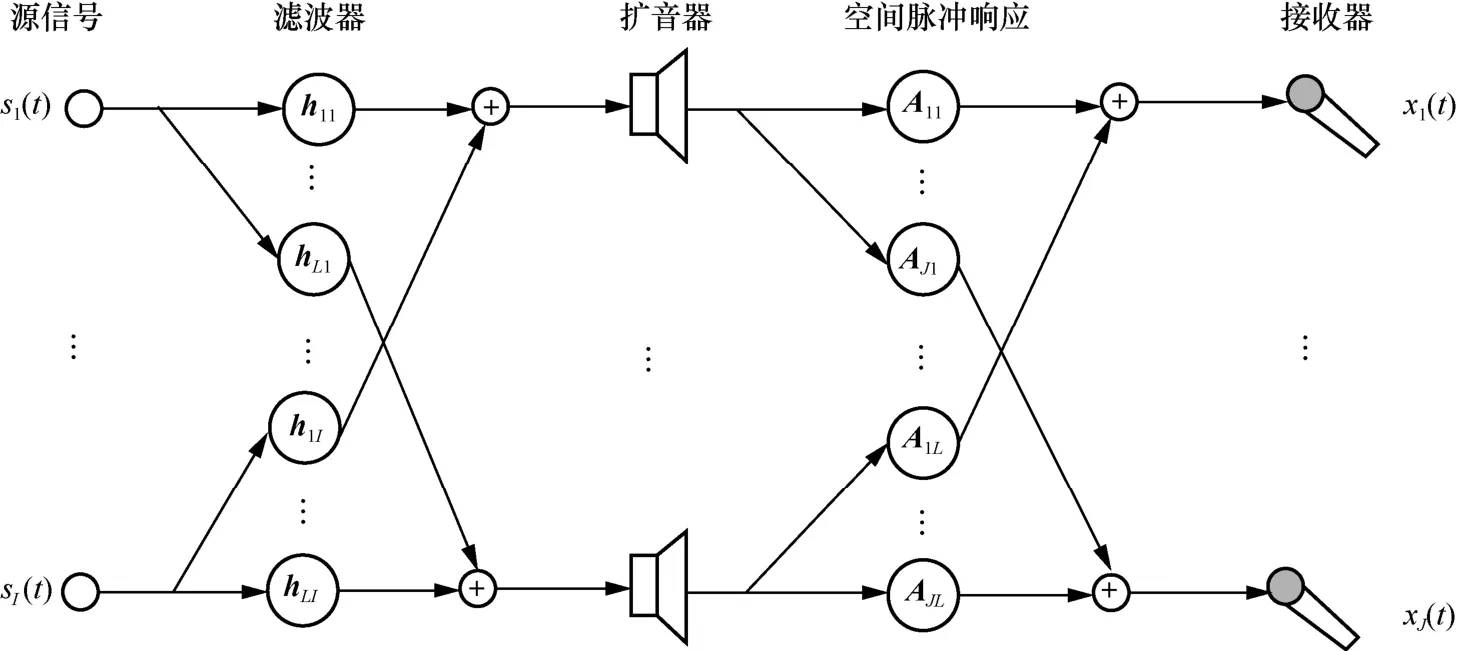
ОӘБЛ¶ЁБҝГиКцИ«ҫЦВціеНшВзКөПЦөДИҘ»мПмР§№ыЈ¬Ҫ«ҝЙёРЦӘ»мПмБҝ»ҜЈЁnPRQ,perceivable reverberation quantizationЈ©¶ИБҝЧчОӘЖАјЫЧјФт[11]Ј¬өұВціеПмУҰұ»НкИ«ЦШЛЬ»тГ»УРКұјдПөКэі¬№эКұјдСЪұОј«ПЮКұЈ¬nPRQ=0Ј¬ЛөГч»мПмұ»НкИ«ПыіэЈ»·сФтЈ¬nPRQ ФҪҙуЈ¬ВціеПмУҰұ»ЦШЛЬөДР§№ыФҪІоЎЈОӘБЛСйЦӨИ«ҫЦВціеНшВз¶ФІ»Н¬»мПмөДУ°ПмЈ¬Йи¶Ё»мПмКұјдRT ОӘ100Ў«900 msЈ¬ІўУлФӯКјВціеНшВзҪшРР¶ФұИЈ¬КөСйҪб№ыИзНј2 ЛщКҫЎЈПаұИУЪФӯКјВціеНшВзЈ¬ФЪөН»мПмПВЈ¬И«ҫЦВціеНшВзҝЙТФНкИ«Пыіэ»мПмЈ¬К№nPRQЗчУЪ0Ј»ФЪёЯ»мПмПВЈ¬И«ҫЦВціеНшВзҝЙТФПчИх»мПмөДУ°ПмЈ¬МбёЯРЕәЕөДЦКБҝЎЈ

Нј2 И«ҫЦВціеНшВзИҘ»мПмР§№ы
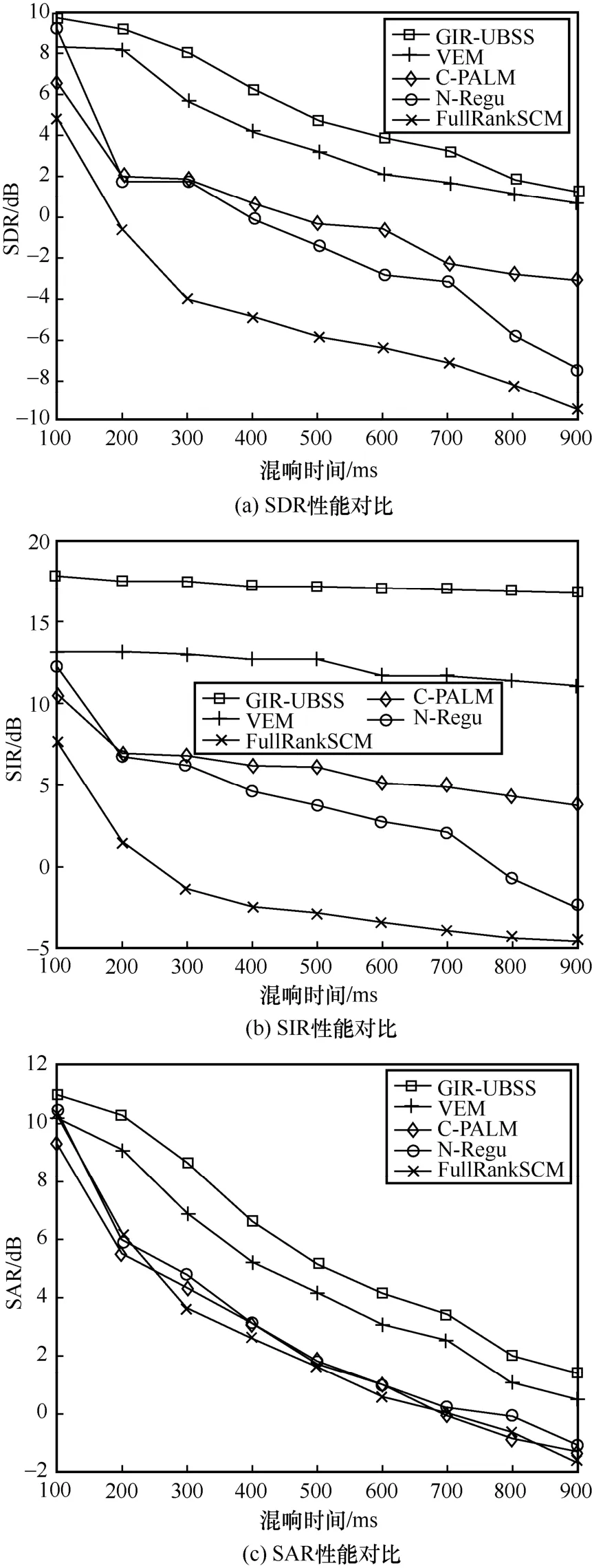
3.3 ·ВХжКөСй1ЈәУўОДУпТфРЕәЕЗ·¶Ёҫн»эГӨФҙ·ЦАл
ОӘБЛСйЦӨGIR-UBSS Лг·ЁөДУРР§РФәНУЕФҪРФЈ¬КЧСЎ3 ЧйУўОДУпТфРЕәЕЈ¬Изұн1 ЛщКҫЎЈКэҫЭјҜАҙФҙУЪ№ъјКЙП№«ҝӘөДРЕәЕ·ЦАлЖАјЫКөСйКэҫЭЎЈұҫОДҙҙҪЁТ»ёцБҪНЁөАИэУпТфФҙөДЗ·¶Ёҫн»э»мөюЈ¬АыУГGIR-UBSS Лг·ЁҪшРР·ЦАлЈ¬Н¬КұУлјёЦЦұИҪПБчРРөДГӨФҙ·ЦАлЛг·ЁҪшРР¶ФұИЈ¬КөСйҪб№ыИзНј3 ЛщКҫЎЈҙУНј3 ҝЙЦӘЈ¬ЛжЧЕRT өДФцјУЈ¬Лг·ЁөД·ЦАлРФДЬПВҪөЈ¬ХвКЗУЙУЪRT өДФцјУҙшАҙБЛ»мПмөДёҙФУРФЈ¬өјЦВ·ЦАлФҪАҙФҪА§ДСЈ¬ЖдЦРЈ¬SDR әНSAR өДКэЦөПВҪөұИҪПГчПФЈ¬ө«КЗSIR өДЦөұИҪПОИ¶ЁЈ¬ХвКЗУЙУЪұҫОДЛщЙијЖөДИ«ҫЦВціеПмУҰНшВзҝЙТФәЬәГөШјхИхRT өДУ°ПмЈ¬ҙУ¶шөГөҪОИ¶ЁөДSIRЎЈ

ұн1 ·ВХжКөСй1Јә3 ЧйУўОДУпТф
Нј3 УўОДУпТфРЕәЕЗ·¶Ёҫн»эГӨФҙ·ЦАлРФДЬ¶ФұИ
ФЪёЯ»мПм»·ҫіПВЈ¬¶ФұИЛг·Ё·ЦАлРФДЬПВҪөСПЦШЈ¬ЙхЦБК§Р§Ј¬¶шGIR-UBSS Лг·ЁТАИ»ҝЙ»сөГҪПәГөД·ЦАлҪб№ыЎЈУл¶ФұИЛг·ЁЦРЧоәГөД·ЦАлҪб№ыПаұИЈ¬GIR-UBSS Лг·ЁөГөҪөДSDRЎўSIR әНSAR Цө·ЦұрМбёЯБЛФј1 dBЎў5 dB әН1 dBЈ¬ёГКөСйСйЦӨБЛGIR-UBSSЛг·ЁФЪёЯ»мПм»·ҫіПВ·ЦАлЗ·¶Ёҫн»эУпТф»мөюРЕәЕөДУРР§РФәНУЕФҪРФЎЈ
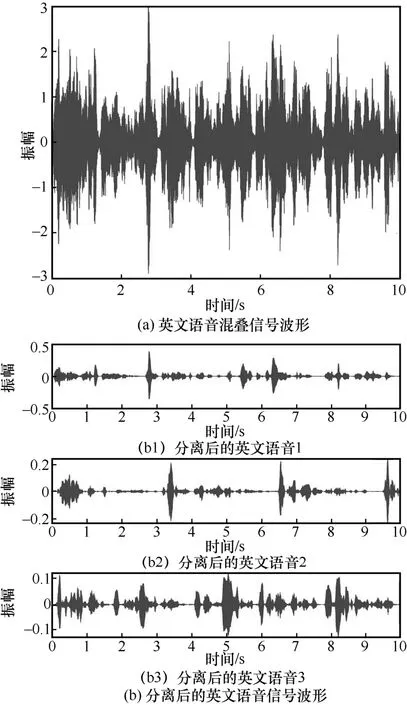
БнНвЈ¬ОӘБЛҙУКУҫхөДҪЗ¶ИҪвОцУўОДУпТф»мөюРЕәЕ·ЦАлЗйҝцЈ¬ҝЙКУ»Ҝ»мПмКұјдОӘ300 ms ПВөДФӯКјУўОДУпТф»мөюРЕәЕІЁРОТФј°·ЦАләуөДУўОДУпТфРЕәЕІЁРОЈ¬ИзНј4 ЛщКҫЎЈ
Нј4 УўОДУпТф»мөюРЕәЕІЁРОТФј°·ЦАләуөДУўОДУпТфРЕәЕІЁРО
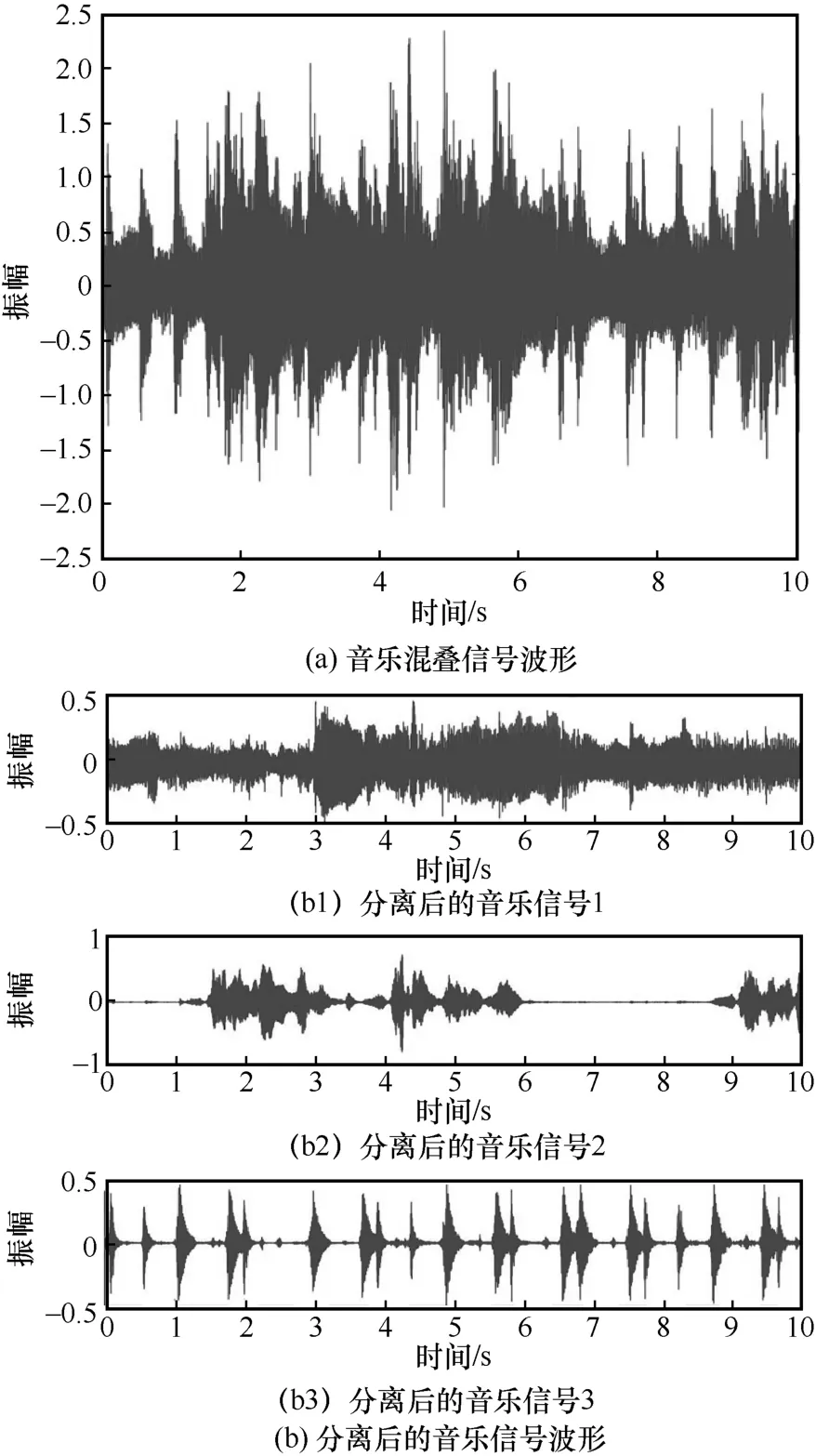
3.4 ·ВХжКөСй2ЈәТфАЦРЕәЕЗ·¶Ёҫн»эГӨФҙ·ЦАл
ОӘБЛСйЦӨGIR-UBSS Лг·Ё¶ФТфАЦ»мөюРЕәЕөДУРР§РФәНУЕФҪРФЈ¬ІвКФ3 ЧйТфАЦЗ·¶Ёҫн»э»мөюРЕәЕЈ¬СЎИЎөДФҙРЕәЕИзұн2 ЛщКҫЈ¬ёГТфАЦРЕәЕ°ьАЁјӘЛыЙщЎўИЛЙщәН№ДЙщЈ¬И«КұіӨОӘ25 sЈ¬ІЙСщЖөВКОӘ44.1 kHzЈ¬ОӘБЛјхЙЩ·ЦАлЛщРиөДКұјдЈ¬ұҫОДКөСйҪ«РЕәЕҪШ¶ПОӘ10 sЈ¬ПВІЙСщЦБ16 kHzЈ¬ұЈіЦУлКөСй1 өДТ»ЦВРФЈ¬ГӨФҙ·ЦАлҪб№ыИзНј5 ЛщКҫЎЈ

ұн2 ·ВХжКөСй2Јә3 ЧйТфАЦРЕәЕ

Нј5 ТфАЦРЕәЕЗ·¶Ёҫн»эГӨФҙ·ЦАлРФДЬ¶ФұИ
ҙУНј5 ҝЙЦӘЈ¬ЛжЧЕRT өДФцҙуЈ¬Лг·ЁөД·ЦАлРФДЬУлФӨЖЪ»щұҫТ»ЦВЎЈУл¶ФұИЛг·ЁЦРЧоәГөД·ЦАлҪб№ыПаұИЈ¬GIR-UBSS Лг·ЁөГөҪөДSDRЎўSIRЎўSAR Цө·ЦұрМбёЯБЛФј6 dBЎў7 dB әН6 dBЎЈёГКөСйСйЦӨБЛGIR-UBSS Лг·ЁФЪёЯ»мПм»·ҫіПВ·ЦАлЗ·¶Ёҫн»эТфАЦ»мөюРЕәЕөДУРР§РФәНУЕФҪРФЎЈ
Ул·ВХжКөСй1 өДҪб№ы¶ФұИҝЙ·ўПЦЈ¬GIR-UBSSЛг·ЁФЪ·ЦАлТфАЦ»мөюРЕәЕұнПЦіцёьәГөДУЕФҪРФЎЈХвКЗУЙУЪұҫОДАыУГБЛ·ЗёәҫШХу·ЦҪвФҙДЈРНЈ¬ПаұИУЪУпТфФҙЈ¬ТфАЦФҙҝЙТФұ»ҪПРЎКэДҝөДФҙіЙ·ЦұнКҫЈ¬ёьККУГУЪ·ЗёәҫШХу·ЦҪвДЈРНЈ¬ҙУ¶ш»сөГёьәГөД·ЦАлҪб№ыЎЈ
ОӘБЛҙУКУҫхөДҪЗ¶ИҪвОцТфАЦ»мөюРЕәЕ·ЦАлЗйҝцЈ¬ҝЙКУ»Ҝ300 ms ПВөДФӯКјТфАЦ»мөюРЕәЕІЁРОТФј°·ЦАләуөДТфАЦРЕәЕІЁРОЈ¬ИзНј6 ЛщКҫЎЈ
Нј6 ТфАЦ»мөюРЕәЕІЁРОТФј°·ЦАләуөДТфАЦРЕәЕІЁРО
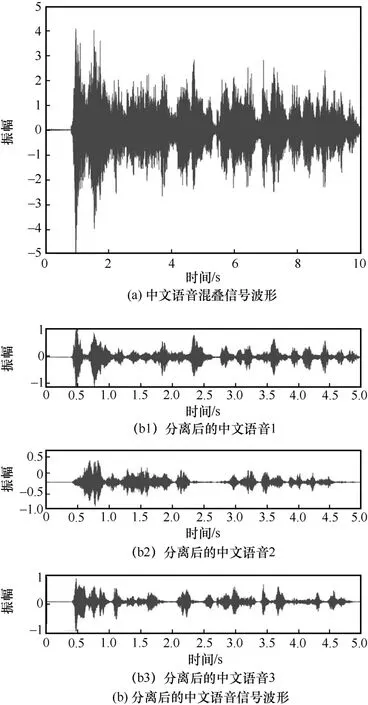
3.5 ·ВХжКөСй3ЈәЦРОДУпТфРЕәЕЗ·¶Ёҫн»эГӨФҙ·ЦАл
ОӘБЛСйЦӨGIR-UBSS Лг·Ё¶ФЦРОДУпТф»мөюРЕәЕөДУРР§РФәНУЕФҪРФЈ¬ІвКФ3 ЧйЦРОДУпТф»мөюРЕәЕЈ¬КэҫЭјҜАҙЧФ№ъДЪ№«№ІЦРОДУпТфКэҫЭјҜЎЈСЎИЎ3 ЧйУпТфРЕәЕЈ¬Изұн3 ЛщКҫЈ¬ГӨФҙ·ЦАлҪб№ыИзНј7 ЛщКҫЎЈУл¶ФұИЛг·ЁЦРЧоәГөД·ЦАлҪб№ыПаұИЈ¬GIR-UBSS Лг·ЁөГөҪөДSDRЎўSIRЎўSAR Цө·ЦұрМбёЯБЛФј1 dBЎў5 dB әН1 dBЎЈСйЦӨБЛGIR-UBSS Лг·Ё¶Ф·ЦАлЦРОДУпТфЗ·¶Ёҫн»э»мөюРЕәЕИФИ»ҫЯУРҪПәГөДУРР§РФәНУЕФҪРФЎЈ

ұн3 ·ВХжКөСй3Јә3 ЧйЦРОДУпТф
Нј7 ЦРОДУпТфРЕәЕЗ·¶Ёҫн»эГӨФҙ·ЦАлРФДЬ¶ФұИ
БнНвЈ¬ОӘБЛҙУКУҫхөДҪЗ¶ИҪвОцЦРОДУпТф»мөюРЕәЕ·ЦАлЗйҝцЈ¬ҝЙКУ»Ҝ»мПмКұјдОӘ300 ms ПВөДФӯКјЦРОДУпТф»мөюРЕәЕІЁРОТФј°·ЦАләуөДЦРОДУпТфРЕәЕІЁРОИзНј8 ЛщКҫЎЈ
Нј8 ЦРОДУпТф»мөюРЕәЕІЁРОТФј°·ЦАләуөДЦРОДУпТфРЕәЕІЁРО
3.6 Лг·Ё¶ФХжКөФлЙщөДОИҪЎРФ·ЦОц
ОӘБЛСйЦӨGIR-UBSS Лг·Ё¶ФХжКөФлЙщөДОИҪЎРФЈ¬ПЦКөЙъ»оЦРУцөҪөДФлЙщіЎНЁіЈҝЙТФҪьЛЖОӘЗтРО»тФІЦщРОФлЙщіЎЈ¬ИзКұјдПа№ШФлЙщЎўУЙПа»Ҙ¶АБўөДУпТфЖ¬¶О»мәП¶шіЙөД°НІјУпТф»т№Өі§ФлЙщЈ¬ТФј°КТНвІвБҝҫӯіЈКЬөҪёчЦЦЙщФҙЈЁИзҪ»НЁЎўЧФИ»»·ҫіЙщТфөИЈ©өДёЙИЕЎЈұҫОДКөСйІвКФ3 ЦЦХжКөФлЙщЈәУЙЗтРОІъЙъөДёчПтН¬РФФлЙщЈЁisotropic noiseЈ©ЎўУЙПа»Ҙ¶АБўөДУпТфЖ¬¶О»мәП¶шіЙөД°НІјУпТфФлЙщЈЁbabble noiseЈ©ТФј°·зФлЙщЈЁwind noiseЈ©ЎЈИ»әу·Цұр°СХв3 ЦЦФлЙщјУИл·ВХжКөСй1 ЦРөД»мөюУпТфРЕәЕЦР№№іЙә¬ФлЙщөД»мөюРЕәЕЈ¬АыУГGIR-UBSS Лг·Ё¶Ф»мөюРЕәЕҪшРР·ЦАлЈ¬Н¬Кұ¶ФұИОЮФлЙщЈЁwithout noiseЈ©ПВөДГӨФҙ·ЦАлЈ¬КөСйҪб№ыИзНј9 ЛщКҫЎЈҙУНј9ҝЙЦӘЈ¬јУИлІ»Н¬ФлЙщТФәу»сөГөДГӨФҙ·ЦАлҪб№ыУлОЮФлЙщПВөГөҪөДҪб№ыПаЛЖЈ¬СйЦӨБЛGIR-UBSS Лг·Ё¶ФХжКөФлЙщҫЯУРәЬәГөДОИҪЎРФЎЈ

Нј9 ә¬УРХжКөФлЙщөДГӨФҙ·ЦАлРФДЬ¶ФұИ
4 ҪбКшУп
ПЦКөЙъ»оЦРЈ¬ҪУКХөД»мөюРЕәЕНщНщ°йЛжёЯ»мПмөИІ»И·¶ЁТтЛШЈ¬ИзәОПыіэ»тПчИхёЯ»мПмөДУ°ПмЈ¬МбёЯГӨФҙ·ЦАлРФДЬЈ¬ТСҫӯіЙОӘРЕәЕҙҰАнЦРј«ҫЯМфХҪРФәНПЦКөТвТеөДҝОМвЎЈОӘҙЛЈ¬ұҫОДМбіцТ»ЦЦГжПтёЯ»мПмёҙФУ»·ҫіөДЗ·¶Ёҫн»эГӨФҙ·ЦАлЛг·ЁЈ¬НЁ№эЙијЖИ«ҫЦВціеПмУҰНшВзЈ¬јхЙЩВціеПмУҰөДіӨ¶ИЈ¬ПчИхҝЙМэ»мПм»ШЙщөДУ°ПмЎЈҪш¶ш№№ҪЁёЯ»мПм»·ҫіөДКұЖөУт»мөюРЕәЕКэС§ДЈРНЈ¬ЙијЖРВДЈРНПВөДІОКэёьРВ№жФтЈ¬КөПЦФҙРЕәЕөДГӨ·ЦАлЎЈАнВЫ·ЦОцұнГчЈ¬ФЪРВөДКөКұДЈРНёьРВ№жФтПВЈ¬ҝЙөГөҪЖөУтЙПөДФҙРЕәЕЎЈКөСйСйЦӨБЛЛщМбGIR-UBSS Лг·Ё¶Ф·ЦАлЦРУўОДУпТф»мөюРЕәЕЎўТфАЦ»мөюРЕәЕҫЯУРәЬәГөДУРР§РФЎЈБнНвЈ¬НЁ№эУл№ъјКЙПұИҪПБчРРөДГӨФҙ·ЦАлЛг·Ё¶ФұИЈ¬ЦӨКөБЛGIR-UBSS Лг·ЁөДУЕФҪРФЈ¬ТФј°¶ФХжКөФлЙщҫЯУРБјәГөДОИҪЎРФЎЈ